Joining NVIDIA Inception
Lokutor has been accepted into NVIDIA Inception — a program that supports startups revolutionizing industries with AI and accelerated computing.



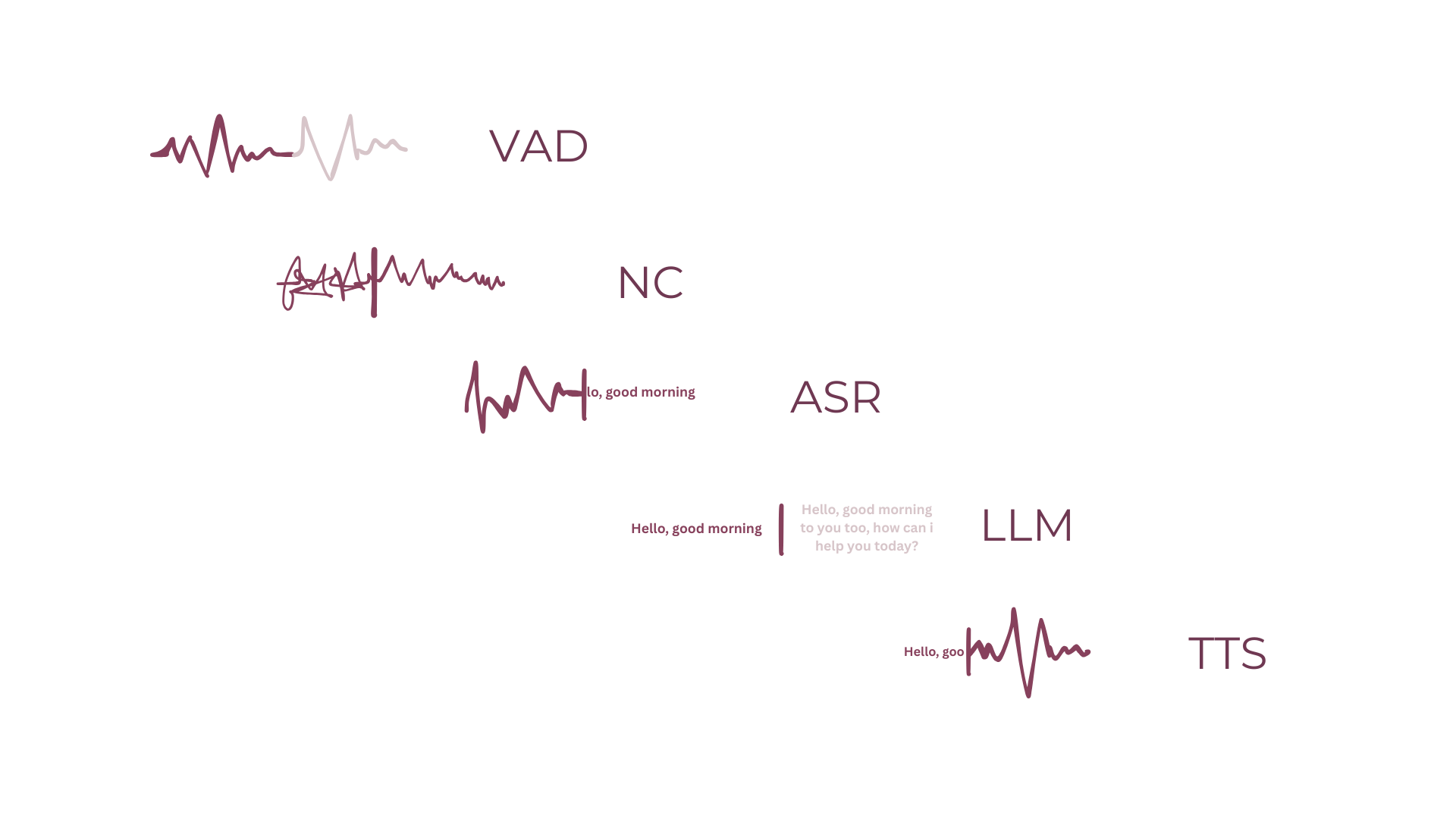
Every model - turn-taking, STT, LLM, and TTS - trained from scratch and optimized for commodity CPUs. No GPU dependency. Sub-450ms end-to-end.
Most voice AI platforms follow the same recipe: stitch together a STT API from one provider, an LLM from another, a TTS from a third - each running on expensive NVIDIA GPUs, each adding 200–300ms of network latency. The result is a fragile cascade that costs too much and feels unnatural.
We took a different approach. Every model - Vela (turn-taking), Psst (noise suppression), our fine-tuned LLM, STT, and Versa (TTS) - is trained from scratch and hand-optimized for ARM and x86 CPUs. No GPU overhead. No third-party dependencies. Full control over quality and latency.
The same cascade architecture, rebuilt model by model for maximum efficiency. Sub-450ms on a standard server.
Our models are trained on MareNostrum 5, one of Europe's most powerful supercomputers, through the Barcelona Supercomputing Center AI Factory program. We work closely with NVIDIA (Inception partner) and AWS to push CPU-based inference to its limit. This is European deep tech - building voice AI infrastructure from the ground up.
1 Customer Training • 2 Corporate Formation • 3 Sales Conversations • 4 Support Interactions
[instructive tone] Okay, let's walk through the new dashboard interface together. Whenever you're ready, click Start Module and I'll explain each section as we go.
[welcoming tone] Welcome to the team. Our onboarding syllabus will guide you through the initial setup, HR policies, and an introduction to our cultural values. Let's begin.
[confident tone] Hi there. I noticed you were exploring our enterprise plans. I'd love to show you how our custom solution can significantly increase your conversion rates.
[empathetic tone] I'm so sorry to hear you are experiencing issues with your account. Let me pull up your details right away, and we will get this sorted out for you.
Integrate Lokutor in minutes with our SDKs and comprehensive documentation.
import { VoiceAgentClient, VoiceStyle, Language } from '@lokutor/sdk';
const client = new VoiceAgentClient({
apiKey: 'your-key',
prompt: 'You are a helpful and friendly AI assistant.',
voice: VoiceStyle.F1,
language: Language.ENGLISH,
visemes: true,
});
client.on('transcription', (text) => console.log('You:', text));
client.on('response', (text) => console.log('Agent:', text));
client.on('visemes', (visemes) => animateMouth(visemes));
client.on('status', (status) => console.log('Status:', status));
await client.startManaged();from lokutor import VoiceAgentClient, VoiceStyle, Language
import os
client = VoiceAgentClient(
api_key=os.environ['LOKUTOR_API_KEY'],
prompt='You are a helpful and friendly AI assistant.',
voice=VoiceStyle.F1,
language=Language.ENGLISH,
)
@client.on('transcription')
def on_transcription(text):
print(f"You: {text}")
@client.on('response')
def on_response(text):
print(f"Agent: {text}")
@client.on('status')
def on_status(status):
print(f"Status: {status}")
client.start_conversation()Lokutor has been accepted into NVIDIA Inception — a program that supports startups revolutionizing industries with AI and accelerated computing.
Lokutor TTS is now available as a community integration for Pipecat — the open-source framework for voice and multimodal conversational AI. Install with pip install pipecat-lokutor.
Lokutor has been selected to join the Barcelona Supercomputing Center's AI Factory — a program supporting cutting-edge AI startups with Europe's most powerful supercomputing infrastructure.
Discover how our new noise suppression technology transforms voice AI in real-world environments, from busy cafes to windy streets.
Introducing Vela, our purpose-built turn detection model that predicts when a speaker is about to finish their turn — enabling sub-200ms response gaps without clipping.
Try the world's most efficient voice AI platform. Pick a voice and start a conversation right now - no sign-up required.