AI Phone Calls
Power natural, ultra-responsive conversations for automated calls. Our 100ms average latency makes AI feel truly human and interruption-ready.
We have rebuilt the audio synthesis stack to establish a new standard for human-machine interaction: sub-100ms latency without compromise.
Lokutor was founded to solve the fundamental latency bottleneck in vocal AI. While the industry has singularily focused on increasing model parameters, we identified that for machines to truly converse, speed is the primary variable. Legacy systems rely on sluggish, sequential architectures that result in unnatural delays, breaking the rhythmic flow of human dialogue.
Our mission is to forge the engine for immediate exchange. By returning to first principles, we have engineered an inference pipeline that delivers emotive, high-fidelity speech in under 100 milliseconds. We believe that expressiveness is defined by immediacy: a voice that fails to react in real-time is merely a playback device; a voice that responds at the speed of thought is a living interface.
Through relentless optimization of our neural architecture, Lokutor provides the foundational technology for the next generation of interactive AI agents, reactive environments, and seamless human-machine collaboration.
Meet Versa, our flagship voice model named after the core of human exchange: conversation. It isn't just an update; it's a completely new architecture designed for speed.
While traditional models process audio sequentially, Versa anticipates flow. By optimizing the data path between the neural encoder and the speaker, we have achieved a system that performs speech in real-time, currently powering the fastest Spanish and English agents at global scale.
Versa also includes advanced viseme support for perfect lip-sync synchronization, enabling seamless integration with avatars, virtual assistants, and gaming characters. Our viseme data provides precise mouth shapes and facial expressions that match the generated speech, creating truly immersive visual experiences.
Power natural, ultra-responsive conversations for automated calls. Our 100ms average latency makes AI feel truly human and interruption-ready.
Create seamless meeting experiences where the AI reacts instantly to participant responses. Perfect for high-scale collaboration and virtual gatherings.
Bring NPCs to life with real-time voices. Ultra-low latency ensures that game immersion is never compromised by delayed speech.
Enable robots and IoT devices with local voice synthesis. Ultra-low latency and privacy-focused TTS runs entirely on-device for autonomous interactions.
The performance of Lokutor is the result of a scientific paradigm shift. While legacy systems rely on heavy transformer blocks and generic vocoders, we have optimized the foundational layers of speech synthesis based on research in Text-Speech Alignment and Generative Flow Matching. By implementing novel position embeddings, we achieve perfect rhythmic synchronization without the overhead of massive attention matrices.
Comparison of our model's high-fidelity character voice generation (top) versus our closest competitor's robotic artifacts (bottom).
Lokutor utilizes a streamlined Flow-Matching architecture that bypasses the traditional bottlenecks of AI speech. It begins by mapping raw text characters into a low-dimensional latent space via a separate Conditional Flow Matching (CFM) core, predicting a vector field that reshapes random Gaussian noise into structured speech DNA in a single, non-recursive pass. This compressed 12.5Hz latent representation is then fed into a Causal ConvNeXt Decoder, achieving our signature 100ms Time-to-First-Byte.
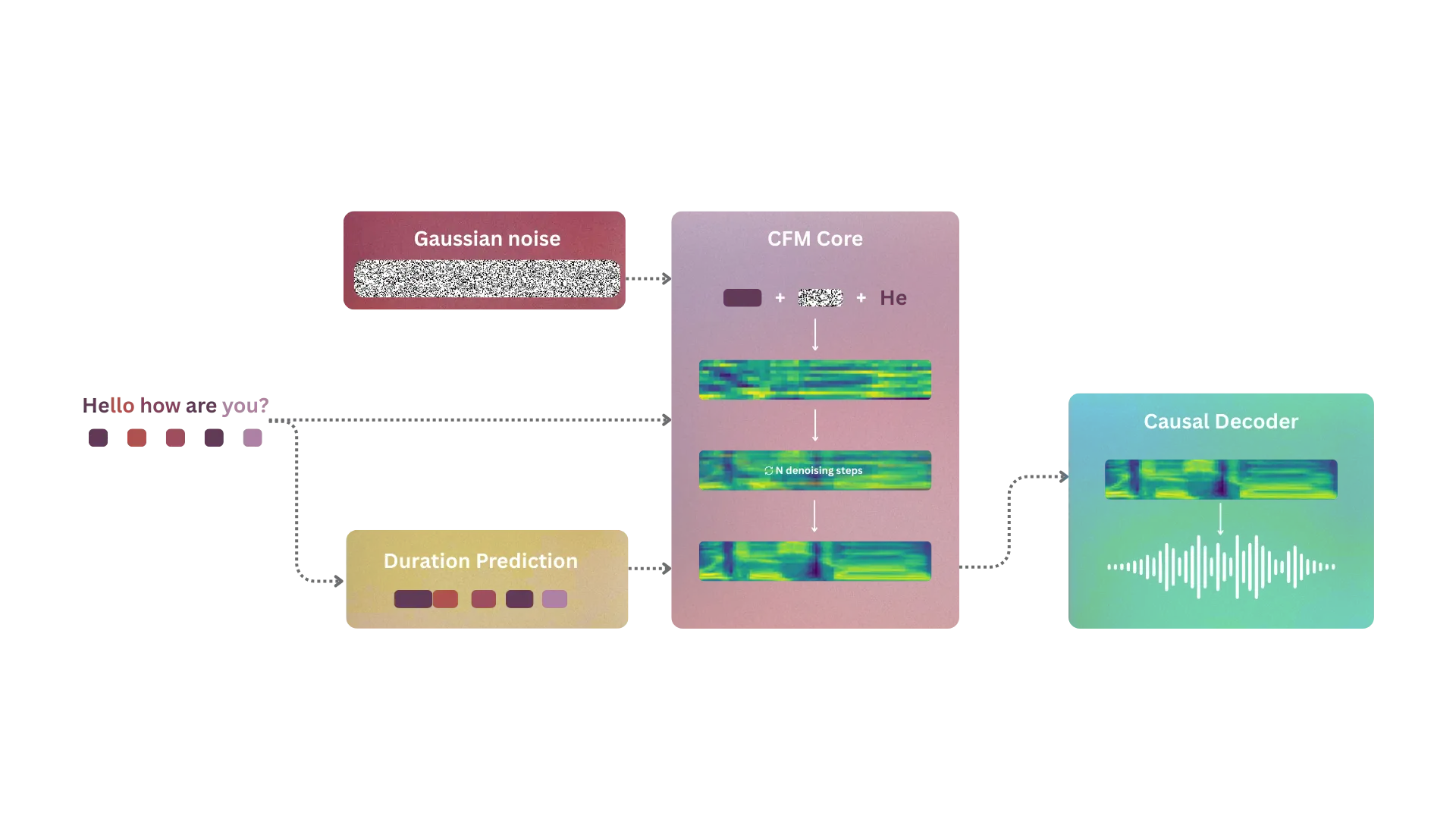
Streamlined Flow-Matching Architecture: From CFM Latent Core to Causal ConvNeXt Decoder.
We believe that accessibility is as important as performance. Our platform is engineered to be developer-first, offering the tools you need to build production-ready voice applications in record time.
Leverage our high-performance API to integrate Lokutor's ultra-low latency voices into your existing infrastructure. Our comprehensive documentation provides everything you need to get started quickly.
Our advanced viseme system provides precise mouth shapes and facial expressions that perfectly synchronize with generated speech. Get real-time viseme data alongside audio for seamless avatar animation, virtual assistants, and gaming characters. Perfect for creating immersive visual experiences where every word is matched with accurate lip movements.
We're actively expanding our capabilities with new voices, voice cloning features, and additional languages. Our team is constantly improving performance and adding innovative features to push the boundaries of real-time voice AI.
SDKs Coming Soon: While we don't have native SDKs available yet, we're actively developing them for popular languages and platforms. Stay tuned for updates!
Have specific requirements or feature requests? We're open to developer feedback and collaboration. Reach out to us at contact@lokutor.com with your ideas.
Our proprietary engine delivers voice synthesis at 100ms end-to-end latency. While competitors average 300ms, that 200ms gap is the difference between an immediate human response and a perceptible AI delay that breaks natural conversation flow.

We are moving from 'Command and Control' to 'Conversational Symbiosis'. Why the best interface of the future is no interface at all.
We're open-sourcing the Go orchestrator that powers our high-performance voice agents. Learn how to build full-duplex voice applications with VAD, Barge-in, and pluggable providers.
The architectural secret behind Versa's speed. Learn how Flow Matching revolutionizes voice synthesis by moving past slow, sequential processing.
Detecting AI voice fraud requires more than just classifiers. We need invisible, mathematical guarantees embedded in the sound wave itself. Restoring trust in the era of deepfakes.
Why is everyone moving away from Transformers for audio? A deep comparison of Auto-Regressive architectures (ElevenLabs, OpenAI) vs. Flow Matching (Lokutor) on latency, stability, and variable costs.
We are building the infrastructure for a world that talks back. Whether you're an enterprise transitioning to voice or a researcher pushing the limits of flow matching, we want to hear from you.
Interested in enterprise infrastructure, custom training, or joining our research team? We're always looking for talent and institutional partners.
Need architectural guidance on integrating ultra-low latency voice into complex systems?
Join our early access program to get the latest SDK features and API updates.
Read Documentation →